

최근 IBM의 왓슨, 구글의 음성인식, 애플의 시리 등의 인공지능 기술의 발전이 하루가 멀다하고 눈부신 성장을 보여주고 있는 이유 중에 큰 축을 차지하는 기술이 바로 머신러닝과 머신러닝 기법 중에 급부상 중인 딥러닝 기법이다. 특히 딥러닝은 근래 들어 빅데이터와 하드웨어 등 연관분야의 발전에 힘입어 탁월한 성능을 보여주고 있으며, 얼굴인식, 음성인식 등의 인공지능 분야 기술 실용화에 앞장서며 기술적 메인스트림이 되어가고 있다. 이러한 인공지능, 머신러닝, 딥러닝의 개념에 대해 알아보고 현재 산업계의 동향과 함께 앞으로의 광고분야에서의 역할과 기회에 대해서 짚어보고자 한다.
글 ┃ 곽동민 딥큐먼 인공지능 연구 그룹 (with 박세원, 이한남)
1. 인공지능> 머신러닝>딥러닝이란?
인공지능이란 어원 그대로 사람의 지능을 기계적으로 모사하는 컴퓨터 사이언스의 한 분야다. 사람의 지능적인 행동을 컴퓨터로 처리하기 위해서 눈·귀·입의 역할과 언어를 이해하기 위한 처리방법 등이 연구되며 각각을 비전, 자연언어처리, 음성인식·합성 등의 분야로 나눠 연구를 진행하고 있다. 특히 이러한 인공지능 분야의 문제를 해결하기 위해 가장 널리 쓰이는 기법으로는 머신러닝(기계학습)이라는 기법이 있으며 최근까지도 활발히 연구되어 전 방위적으로 산업계에 활용되고 있다. 그럼 머신러닝이란 무엇인지 간략히 알아보자 .
머신러닝이란 관찰된 데이터를 통해 목적에 맞는 해답을 찾기 위한 메타프로그래밍(알고리즘을 통해 자동으로 만들어지는 프로그램)이라고 할 수 있다. 여기서 해답이란 분류, 예측, 군집화, 추천 등이 될 수 있으며 이 해답을 찾기 위해 다양한 알고리즘에 데이터세트를 입력하여 새로운 프로그램 또는 모델을 창조해내는 작업이라고 할 수 있다. 그리고 각 해답을 찾기 위해 머신러닝 알고리즘에 입력하는 데이터세트를 훈련용 데이터세트라고 하는데, 이 데이터세트를 어떻게 구성하는가에 따라 지도학습과 비지도학습으로 나눌 수 있다.
지도학습이란 말 그대로 특정 데이터에 대한 해답을 제시, 지도함으로써 알고리즘을 통해 배워나가는 과정이고 비지도학습이란 특정 데이터에 대한 해답을 제시하지 않은 상황에서 알고리즘 스스로 데이터들간의 관계나 특이성을 배워나가는 과정이라고 할 수 있다. 지도학습이 실생활에 적용된 사례를 보면 얼굴 인식, 자동차 번호판 인식, 신용카드 도난방지 시스템 등의 분류나 인식 문제에서 쉽게 찾아볼 수 있다. 비지도학습의 사례로는 고객 데이터베이스를 통해 타깃 마케팅의 자료로 활용하기 위한 고객 군집화, 쇼핑몰 등에서 흔히 접하는 장바구니분석을 통한 상품 끼워팔기 등이 있다. 이러한 지도학습과 비지도학습을 ‘꼭 어디에 적용해야 된다’라는 은탄환(Silver bullet)이 있는 것은 아니며 해결하기 위한 문제가 무엇인가, 그리고 그것을 해결하기 위해 관찰된 데이터는 무엇인가에 따라서 적절한 머신러닝 알고리즘을 선택하게 되고 Trial and Error를 통해 반복적으로 좀 더 나은 해답을 찾아나가게 된다.
이러한 머신러닝의 절차를 다음으로 압축해볼 수 있다.
1.문제의 정의 → 2.데이터의 수집 및 관찰 → 3.관찰된 데이터의 전처리 → 4. 전처리된 데이터들의 특징을 추출 → 5. 목적에 맞는 알고리즘 선택 및 훈련 → 6. 검증 → 7. 모델해석 → 8.최종 솔루션(모델) 선택
즉 2~7의 과정을 수도 없이 반복하여 좀 더 나은 결과를 찾아나가는 것이 머신러닝의 과정이라고 볼 수 있으며 7번 단계의 모델에 대한 해석과정을 얼마나 손쉽게 접근할 수 있는가에 따라서 화이트박스 모델과 블랙박스 모델로 나뉘며, 데이터의 확률분포를 통해 배워나가는가의 유무에 따라서 Generative model, Discriminative model로 나눠볼 수 있다. 여기서 화이트박스란 모델 내부를 속 시원히 내다볼 수 있는 모델들을 들 수 있으며 이를 통해 어떤 특징이 모델에 영향을 주었는지 안 주었는지 등이 파악된다. 반면 블랙박스 모델은 모델 내부를 속 시원히 내다보기 힘든 모델들을 일컬으며 여러 단계를 거치거나 대략적으로만 모델에 영향을 미친 특징들을 파악할 수 있다.
1-1. 딥러닝이란
딥러닝은 머신러닝 기법 중에 하나로 말 그대로 깊은 또는 심화된 학습의 과정을 일컫는다.
위에서 논의한 머신러닝의 과정과 별반 다르지 않으며 특히, 블랙박스 모델로 잘알려진 뉴럴넷(Artificial Neural Network)을 통해 태동되었다. 본래 뉴널넷은 인간의 뇌 구조와 정보전달과정을 모사하여 만들어낸 수학적 모델로 1950년대 퍼셉트론으로부터 시작되어 현재까지 이르게 되었다. 뉴럴넷은 입력과 출력이라는 두 가지 레이어 구조의 얕은(Shallow) 아키텍처로 시작하여 중간에 숨은(Hidden) 레이어가 쌓여나가면서 복잡하고 깊은(Deep) 아키텍처로 발전해오고 있으며 이들 사이의 관계를 파라미터를 통해 조정할 수 있는 구조와 메커니즘을 갖고 있다. 이렇게 정의된 아키텍처에 적당한 양의 데이터를 입력하여 선형 맞춤과, 비선형 변환을 통해 각 레이어 간의 관계인 파라미터들을 갱신하는 반복적인 과정을 통해 복잡한 문제들을 해결해 나간다. 즉 추상적으로 표현하자면 데이터들을 구분할 수 있도록 우선 구분선을 긋고 이 공간들을 구부리거나 합하는 것을 반복하여 최대한 잘 구분할 수 있는 구분선을 만들어나가는 과정이 뉴럴넷의 학습 방법이자 딥러닝의 방법이다.
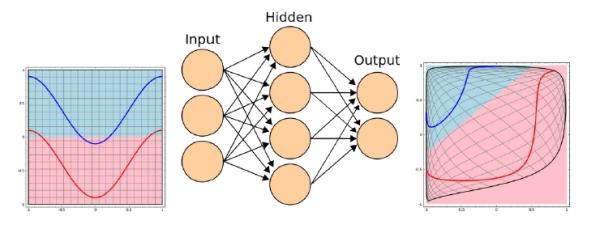
뉴럴넷에서 데이터를 학습해나가는 과정 출처: http://colah.github.io/
이러한 과정에 있어 중요한 것은 데이터이며, 이 데이터를 파라미터로 표현하여 최대한 데이터에 근접하게 갱신하고 조정하는 과정이 최적화(Optimization)이라고 한다. 또한 뉴럴넷의 아키텍처는 사용하는 데이터에 맞게 설계되어야 한다. 예를 들어 파라미터가 너무 많거나 적을 경우에는 Overfitting, Underfitting 등의 문제가 발생할 수 있으며 기껏 열심히 학습해 놓은 뉴럴넷 모델이 그릇된 결과를 내놓는 경우가 발생한다. 결론적으로 딥러닝은 숨은 레이어가 많은 딥뉴럴넷 아키텍처에서 많은 양의 데이터를 학습하는 과정이라고 할 수 있겠다(이는 레이어와 레이어 사이의 파라미터의 양에 따라 정보의 학습 수용력이 결정되는 것을 뜻하며, 딥아키텍처라면 당연히 많은 양의 학습 수용력을 갖게 될 것이다).
1-2. 그렇다면 왜 지금 이 시기에 딥러닝이 부흥하고 있는가?
위에서도 언급했듯이 뉴럴넷은 1940년대부터 오랜 시간 발전되어온 방법론으로 80년대에 ‘역전파’라는 최적화 방법이 소개되면서 다양한 분야에 적용되어 절정기에 이르게 되지만 이후 90년대에 들어 한계를 드러내기 시작하면서부터 암흑기를 만나게 된다(이에 반해 비선형 함수를 이용한 커널 방법론-SVM, GMM 등-들이 급부상하면서 대세를 이루게 되었다).
과거 이러한 한계를 갖게 된 주요 요인으로는 깊어지는 레이어 구조에서 파라미터들이 최적의 값을 찾기 어려워지는 Local Minima 함정에 빠지거나 많은 양의 연산을 감당할 수 있는 하드웨어의 부족과 오류 역전파 알고리즘을 통해 발생하는 오차 신호가 사라지는 현상 (Vanishing gradient problem) 등의 학습 알고리즘 부재가 크게 작용했다.
하지만 인터넷 및 소셜 미디어 등을 통해 생성되는 거대한 데이터와 그래픽하지만 인터넷 및 소셜 미디어 등을 통해 생성되는 거대한 데이터와 그래픽 카드, 클라우드 인프라스트럭처 등의 하드웨어 발전으로 인해 과거의 문제점들이 하나 둘씩 해결되어오는 것과 동시에 토론토 대학의 힌튼 교수, 스탠포드의 앤드류 응 교수 등의 석학들이 내놓은 해결 방법들을 통해 급격한 성능의 향상을 이룩하고 있다. 즉, 이들 부흥 요인을 정리해 보면 다음과 같다.
1)Pre-trainig
2006년에 토론토대학교의 힌튼 교수가 제안한 비지도학습의 방법으로 미리 데이터에 대한 확률분포 등을 학습함으로써 노이즈 등을 감소시켜 지역 최저점에 빠지는 함정에서 벗어날 수 있게 되었다.
2)특정추출과 인식을 하나의 뉴럴넷에서 수행
기존의 머신러닝 과정에서 특징추출 단계를 보면 도메인 전문가에 의해 해당 데이터에 대한 특징을 가정하고 추출해 낼 수 있는 알고리즘을 직접 만들어 문제를 해결해 나갔다. 반면 딥러닝에서는 이와 같은 과정을 뉴럴넷 아키텍처 내에 포함시켜 데이터 추출자체도 학습하는 효과를 얻어내어 진정 스스로 학습하는 모데을 추구하고 있다. 계를 들어 이미지 자동 분류 등에서 큰 성공을 거두고 있는 Concolution Neural Net의 Convoltiion Layer 와 Pooling Layer들을 통해 입력된 이미지에서 중요한 특징들을 자동 추출해서 학습해 나가는 것을 볼 수 있다.

출처 : http://karpathy.github.io/ Convolution Neural Net 추출된 특징맵의 모습
3)빅데이터와 GPU
레이어가 깊은 딥뉴럴넷의 경우 많은 수의 파라미터가 존재하며 Overfitting 등의 발생으로 일반화 능력이 저하되어 전체적인 성능 저하로 이어질 수 있다. 반면, 학습 수용력(Capacity)은 증가하기 때문에 매우 많은 수의 학습 데이터가 사용 가능한 경우는 그로부터 많은 정보를 학습할 수 있음을 의미하게 된다. 과거에는 수집하기 어려웠던 대용량의 대이터가 이제는 유튜브나 플리커, 트위터 등의 소셜미디어를 통해 구할 수 있고 정제하는 작업 또한 CrowdSourcing 서비스(Mechanical Turk) 등을 통해 적은 노력과 비용으로 해결 할 수 있게 되었다. 또한 어마어마한 연산량을 CPU가 아닌 좀 더 저렴한 CPU 병렬 프로그래밍으로 해결할 수 있었던 것이 크게 작용했다.
1-3. 딥러닝의 미래
현재 산업계에서는 얼굴인식, 객체인식, 음성인식, 자연어처리의 일부 등에서 훌륭한 효과를 내고 있으나 아직 개척하지 못한 영역이 더욱 많아. 그렇다고 이 모든 영역을 딥러닝으로 해결할 수 있는 것 또한 아닐 것이다. 하지만 본격적으로 다뤄지기 시작한 시점으로 볼 때 아직 딥러닝은 태동하기 시작하는 단계라는 것은 부정할 수 없을 것이며 이것이 앞으로의 미래를 밝게 점쳐볼 수 있는 대목이다. 특히 구글이나 스탠포드 등에서 연구된 자동 이미지 캡션 생성시스템 등의 추세로 볼 때 기존에 각 인공지능의 각 영역별로 개별적으로 진행되어오던 프로젝트나 문제들이 영역을 파괴하고 데이터를 공유하며 샐운 문제를 풀어나가기 시작한 것을 보면 긍정적인 모습을 기대해볼 수 있을 것이다.
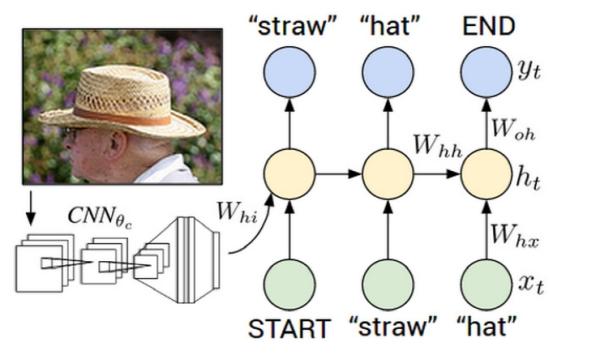
출처 : http://cs.stanford.edu/ 이미지 데이터와 텍스트 데이터를 동시에 활용
또한 긍정적인 미래와 더불어 지속적으로 데이터와 하드웨어 인프라(GPU 병렬처리 등), 다양한 방법론 등이 개발돼야만 할 것이다. 그리고 과거 뉴럴넷이 그래왔듯이 언젠가는 새로운 방법론이나 기존의 커널 방법론들이 지금에 딥러닝의 문제점을 보완하거나 더 나은 성능으로 자리매김할 수 있기 때문에 어느 한 분야만을 고집해서는 안 될 것이며, 골고루 이 분야의 트렌드를 파악해 두는 것이 효과적일 것으로 사료된다.
2. 현재 산업계의 트렌드

인공지능 관련 분야의 업체 리스트 출처 : http://www.shivonzilis.com/
위의 그림을 보면 현재 인공지능 관련 분야 업체들의 리스트를 한눈에 볼 수 있다. 특히 딥러닝 분야에 구글이나 페이스북, 바이두의 활약에 두드러지고 있다. 이들은 주로 자사의 검색, 소셜네트워크 서비스에 음성 인식, 이미지 인식, 얼굴 인식 등의 분야에 적용하고 있다. 이들과 반대로 Vicarious, Ersatz lab 등의 작은 규모의 스타트업이 활발하게 움직이고 있으며 이들은 딥러닝 알고리즘과 ‘Machine learning as a service’ 형태로 제공하는 것을 목적으로 연구하고 있다. 그리고 여기서 눈여겨볼 만한 부분으로 ADTECH 업체들을 들 수가 있다. 이들은 주로 머신러닝이나 딥러닝 기술을 바탕으로 웹 및 모바일/웨어러블 디바이스상에서 새로운 방법으로 광고를 조금 더 친숙하게 소비자에게 중요한 정보로서 전달될 수 있도록 연구하거나 소비자의 행태를 분석하고 예측하는 기법 등을 연구하고 있다.
3. 광고업계에서의 역할과 기회
기존 ADTECH분야에서 주로 사용되어지고 있는 문맥광고나 웹브라우저 쿠키 기반의 광고방식은 주의 깊게 살펴봐야 할 것이다. 즉, 광고가 소비자에게 단순 광고가 아닌 중요한 정보로서 전달 될 수 있도록 하거나 단순히 스쳐 지나갔던 제품 정보들을 다시 리마인드 시켜줘서 구매 욕구를 끌어 올리도록 유도하는 행위는 ADTECH에서 중요한 전달 방식일 것이다. Affectiva 사와 같이 동영상 광고를 보는 소비자의 감성을 실시간으로 분석하여 감성을 극대화할 수 있는 영상을 개별적으로 제공한다든지 길거리에 널려있는 오프라인 광고판에서 개별 유저들의 얼굴을 인식하고 그에 따라 각각 다른 영상을 볼 수 있게 제공하는 사례는 매우 흥미로운 사례로 볼 수 있다.
그리고 애플 사의 시리(Siri)와 같은 IPA(Intelligent Personal Assistant) 서비스들은 날로 발전하여 소비자의 행동양식을 스스로 배울 것이며 음성 및 영상 등의 자연스러운 인터페이스(음성, 홀로그램, 가상현실 등)를 통해 웨어러블 디바이스나 사물인터넷으로 연결돼있는 어떠한 디바이스던 간에 소통하며 소비자에게 적절한 답을 줄 것이다. 이러한 지능적인 문제를 해결하기 위한 중요한 기술의 핵심이 머신러닝 및 딥러닝이다. 과거 연구실이나 대학원에서 연구하는 특정인들을 대상으로만 구현되고 활용되어오던 머신러닝 기술 스택들이 이제는 그 장벽을 허물어 누구나가 손쉽게 데이터만 가지고 있다면 클릭 몇 번으로 나만의 머신러닝, 딥러닝 모델들을 만들어 낼 수 있는 시대가 왔다(https://studio.azureml.net/, https://deepcumen.com).1 이들 기술의 흐름과 사용법을 알고 광고인들만의 독창적이고 창의적인 마인드가 융합된다면 15초는 빨리 넘기고 싶은 시간이 아닌 삶을 살아가는 데 있어 중요한 팁이 될 수 있는 귀중한 시간이 될 수 있지 않을까. 또는 그런 세상이 오기를 필자는 기대해본다.![]()

[AD & Technology] "광고분야에서 딥러닝의 역할과 기회"
인공지능 ·
딥러닝 ·
머신러닝 ·
빅데이터 ·
ADTECH ·
GPU ·
이 기사에 대한 의견
( 총 0개 )






































{kind=link}
{kind=link}
{kind=link}
{kind=link}